技术选型背景
模型开发是算法工程师的工作日常,模型算法的效果也决定着业务场景的上限,但是模型要发挥其作用,必须投入到实际生产场景,目前互联网环境下的生产场景主要是针对不同用户需求下的定制化业务服务,而模型要在业务场景下发挥它的价值就需要嵌入到业务服务当中,在这个过程中会面临以下几个问题:
- 模型服务不同于常规的业务服务,常规业务服务的技术瓶颈在处理高并发请求和复杂的业务逻辑,而模型服务的技术瓶颈在CPU密集型计算和预测响应上,所以在请求密集的情况下模型服务会更占用CPU,同时在一次模型预估的时间也会高于常规业务服务的请求逻辑。
- 算法工程师和研发工程师之间的技术栈不同,算法工程师大部分使用python进行特征工程,模型开发,研发工程师更多使用C++,java,Go这种工程能力更健壮的编程语言,因此模型在部署时面临着技术栈上的交流成本。
- 模型是基于数据开发的,所以模型具有一定时效性,当业务场景下数据发生变动,模型自然也需要更新迭代,如果模型简单的嵌入到业务服务当中,就会面临模型更新就要影响到整个业务服务上的改动。
基于上述可能面临的问题,提出基于docker容器的模型部署方式,解决以上问题的同时,该方式还具有以下优点:
- 模型部署在K8S集群环境下,充分利用大规模集群资源
- 不同模型封装在一个docker容器当中,所以模型预估计算相互独立,支持对多个模型进行预估
- 可扩展性强,模型数量可扩展至百个,千个级别
关于Docker容器
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的镜像中,然后发布到任何流行的 Linux或Windows 机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口。
【官方网站】https://www.docker.com/products/docker-desktop
关于算法模型
这里算法不同于传统意义上的计算机算法,主要指机器学习算法,详情可见机器学习综述。而模型就是算法在训练结束后,学习到一组参数或者规则,而这些参数和规则保存在一定格式的文件当中,模型预估的过程就是加载这些文件到内存当中,传入数据特征进行计算,最终计算得到一个结果,不同类型的模型计算得到的结果形式不同,但是多数监督模型是以概率值的形式输出。
经上表述,模型服务化的目的简单来说就是将模型文件中保存的参数或者规则常驻到内存,提供一个API,让服务可以持续输出预测结果,当前主流的服务都采用restful API的方式,因此需要选择一个可以提供restful API的服务框架来实现模型服务化,因为python在算法模型方面有很优秀的第三方库支持,像numpy,sckit-learn, pandas,keras,tensorflow,所以python的服务框架将成为模型部署的首选,但碍于python作为解释性语言在性能上的劣势,可能会对服务性能造成影响,针对这个问题
-
减少服务python原生态代码的循环操作,尽可能使用numpy进行数据处理,sckit-learn库针对特征有很高效一套逻辑,可将特征处理看作另一种方式的模型保存到pkl文件,如同模型文件一样使用。
-
基于上述描述下特征处理的方式,会造成不同特征处理逻辑存在大量文件问题,解决方式采用docker容器将各个模型特征处理文件和模型文件独立存放,在程序启动时,独立运行各个docker容器。
-
对于复杂的深度学习模型,采用谷歌tensorflow-serving的服务框架进行模型预估。
至此,抽象出一套完整的模型集群式部署方案,在符合业务需求的情况下,保证一定的性能。
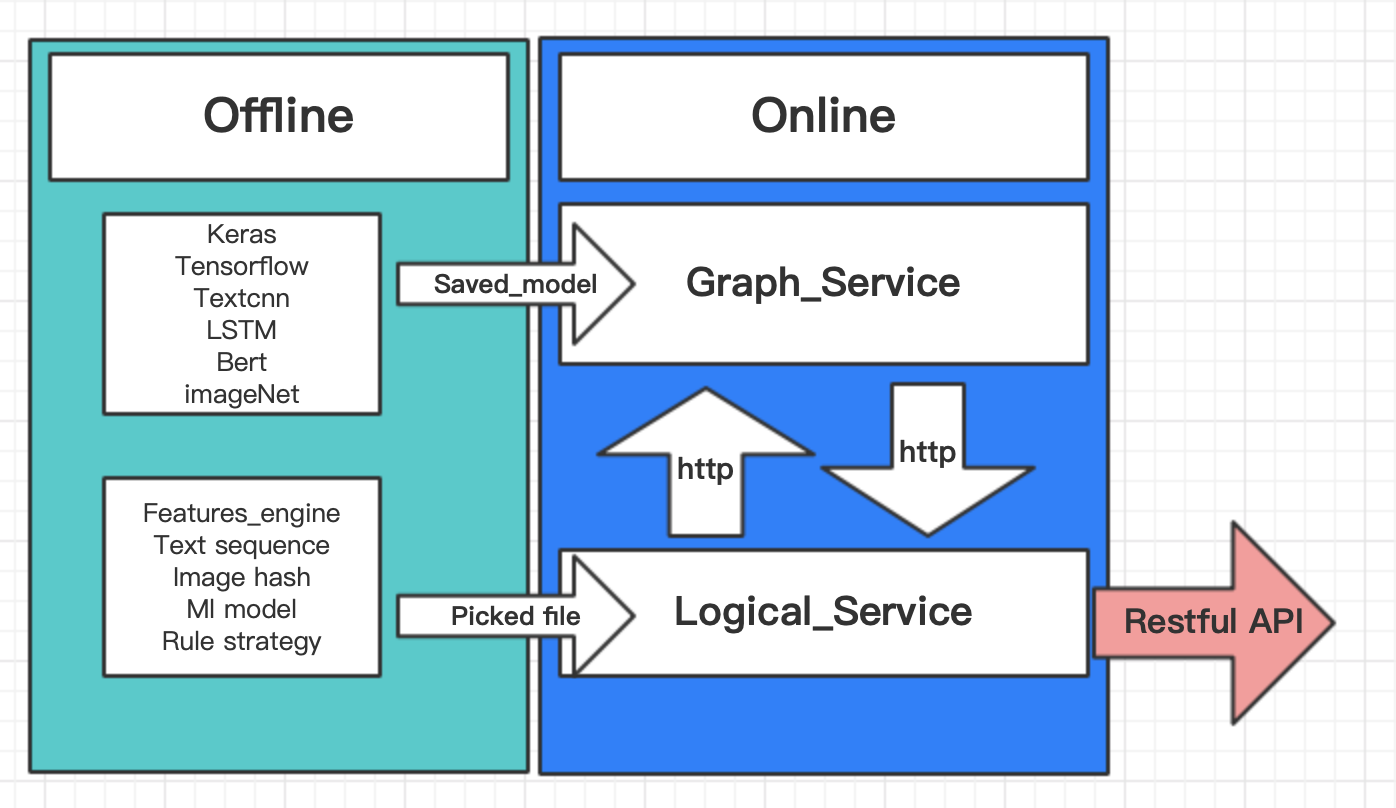
如图所示,将服务切分为图服务,(这里图指tensorflow当中的graph,一个模型即是一个Graph,固暂称其为图服务),逻辑服务(主要指业务逻辑和特征处理逻辑,用于接收场景业务数据和相关数据库的增删改查等),各种服务在各种的容器下,每个服务下的容器数量根据具体需求而定,当前处理方式采用一个模型占用一个容器,独立使用容器计算资源。基于上述架构设计,以谷歌开源的 tensorflow-sevring 项目作为图服务负责模型计算预估,自行开发基于python的Flask服务作为逻辑服务。
关于tensorflow-sevring服务
【官方代码】https://github.com/tensorflow/serving.git
原serving代码由C++编写,需要谷歌开发的bazel编译器进行编译,故而推荐采用docker容器方式,避免编译源码时会出现各种版本环境依赖的错误。具体说明可见项目的readme,很详尽,基本能覆盖大多数需求,若有极特殊需求要定制开发,则需要改动其项目源码,再编译执行。具体改 动规则项目中也有说明。serving对加载的模型有自己的一套格式要求,这种格式命名为saved_model,在tensorflow2.0中这种方式已经成为了一种可选择的存储方式,但是在tensorflow1.x当中需要做一些定制的转换。
saved_model格式

【简单实例】
# 创建 tensorflow model 将模型保存至saved_model
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
model.evaluate(x_test, y_test)
# 关键步骤来来了, 是的,tensorflw2.0就是这么简单
model.save("model/001", save_format="tf")
# 创建 keras model 并将模型保存至saved_model
import os
if not os.path.exists("data"):
os.mkdir("data")
from keras.datasets import mnist
mnist.load_data("data")
from keras.models import Sequential
from keras.layers import Dense, Flatten, Dropout
from keras.utils import to_categorical
(x_train, y_train), (x_test, y_test) = mnist.load_data()
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
model = Sequential()
model.add(Flatten(input_shape=(28, 28)))
model.add(Dense(128, activation="relu"))
model.add(Dropout(0.2))
model.add(Dense(10, activation="softmax"))
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
model.evaluate(x_test, y_test)
# 保存模型为h5文件
model.save("model.h5")
# 打印出模型输入tensor和输出tensor,名称将用于下一步ckpt模型转存为saved_model
print(model.input.name)
print(model.output.name)
关键步骤
将原h5文件转换为ckpt的文件,同tensorflow训练的保存的方式,这里通过脚本 keras_to_tensorflow.py 进行转换,算法组内部有该脚本,可在机器学习服务器获取,转换方法如下:
执行命令
python ~/Code/logos/keras_to_tensorflow.py \
--input_model $PATH/model.h5 \
--output_model $PATH/model.pb \
--save_graph_def true \
--output_meta_ckpt true
执行结束后将得到4个文件,如下:
checkpoint
model.data-00000-of-00001
model.index
model.meta
saved_model
# 将ckpt转存为saved_model格式
import tensorflow as tf
print(tf.__version__)
saver = tf.train.import_meta_graph("model.meta")
# 打印模型的变量,即模型权重
for var in tf.trainable_variables():
print(var)
with tf.Session() as sess:
saver.restore(sess, "model")
graph = tf.get_default_graph()
for tensor in tf.get_default_graph().as_graph_def().node:
print(tensor.name)
# 此处填写前面记录的模型输入名,输出名,这里用input,output代指,具体根据自己模型进行替换
input = graph.get_tensor_by_name("input:0")
output = graph.get_tensor_by_name("output:0")
builder = tf.saved_model.builder.SavedModelBuilder("model/001/")
inputs = {
"inputs": tf.saved_model.utils.build_tensor_info(input),
}
output = {"prediction": tf.saved_model.utils.build_tensor_info(output)}
prediction_signature = tf.saved_model.signature_def_utils.build_signature_def(
inputs=inputs,
outputs=output,
method_name=tf.saved_model.signature_constants.PREDICT_METHOD_NAME
)
builder.add_meta_graph_and_variables(
sess,
[tf.saved_model.tag_constants.SERVING],
{tf.saved_model.signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY: prediction_signature},
main_op=tf.tables_initializer()
)
builder.save()
上述步骤就完成了,得到saved_model文件即可以部署至serving,下面通过构建镜像,启动镜像完成部署,构建镜像Docfile如下:
FROM harbor.sit.hupu.io/base/tensorflow-serving:2.0.0
COPY models/ /models/
EXPOSE 8500 8501
ENV MODEL_CONFIG_FILE=/models/models.config
LABEL XXX="XXX@xxx.com"
其中models.config文件如下:
model_config_list: {
config: {
name:"model_name",
base_path:"/models/model_name/",
model_platform:"tensorflow"
}
}
构建镜像
docker build -t model:1.0 project/model/.
启动容器
docker run -d -p 8500:8500 -p 8501:8501 –name xxx-xxx-tf model:1.0 –model_config_file=/models/models.config
关于python Flask 服务
【说明文档】http://docs.jinkan.org/docs/flask/
【简单实例】
from pickle import load
from flask import Flask, request, Response
app = Flask(__name__)
# load features transformer
with open("transformer.pkl", "rb") as f:
transformer = load(f)
# load ml pkl model
with open("model.pkl", "rb") as f:
model = load(f)
@app.route("/get_score", methods=["POST"])
def predict_func():
""" 模型预测API
:return: json,code:200,data:预测概率
"""
request_data = request.data.decode() # binary 转换为 string
request_json = json.loads(request_data) # json 转换为 dict
x_data = pd.DataFrame(request_json["data"])
x_features = transformer.transform(x_data)
pred = model.predict(x_features)
return Response(json.dumps({"msg": "Successful!", "code": 200, "data": pred}))
@app.route('/health', methods=['GET'])
def health():
""" 服务健康检查
:return: json,code:200
"""
return Response(json.dumps({"health": "status", "code": 200}))
if __name__ == '__main__':
app.run(host="0.0.0.0", port=5000)
- 模型部署
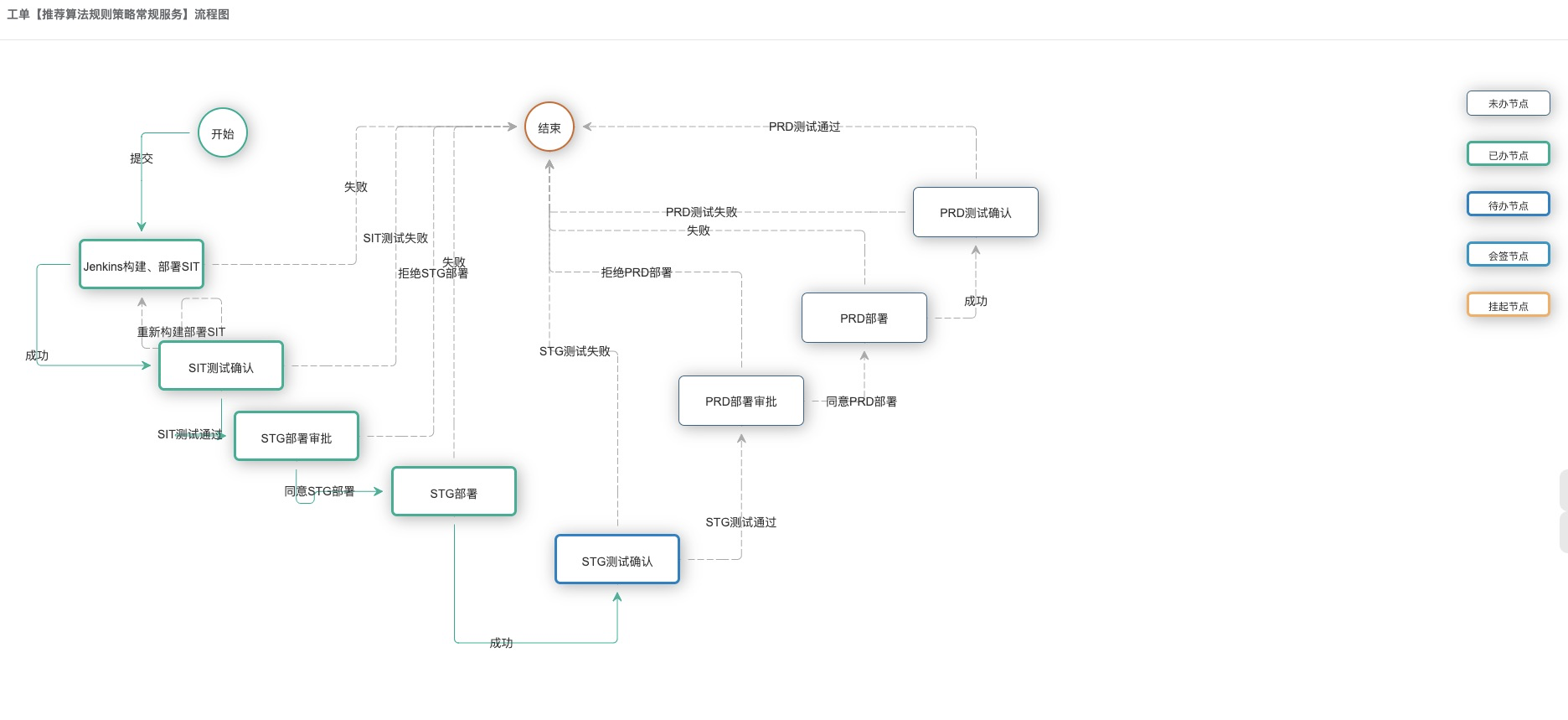
模型部署需要申请提交工单,进行新应用申请,三段式命名,eg:srs-agg-api,之后走应用上线新流程,依旧需要提交工单,通过后项目将自动流转,sit环境 –> stg环境 –> prd 环境。
- 应用流程
- Jenkins 构建监控
- 容器应用日志查询